
Present a proof of your answer.
Microsatellites tends to have a relatively high mutation rate, with mutations frequently involving a gain or a loss of a single repeat during DNA replication. This is thought to occur due to slippage of the DNA as the DNA replication machinery passes over the microsatellite.
The probability of slippage is assumed to increase with the number of repeats, n[t], in the microsatellite at time t.
Part 1:
Let 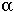 n[t] be the probability that the microsatellite increases by one repeat in a generation.
n[t] be the probability that the microsatellite increases by one repeat in a generation.
Let 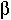 n[t] be the probability that the microsatellite decreases by one repeat in a generation.
n[t] be the probability that the microsatellite decreases by one repeat in a generation.
Write down an equation for the expected value of n[t+1] as a function of n[t]. Simplify your result and answer the following questions:
Assume instead that deletions become more common as the length of the microsatellite increases (perhaps loops form more readily during DNA replication causing more deletions). Let the probability that the microsatellite decreases by one repeat in a generation now equal n[t]2.
Write down the expected value of n[t+1] as a function of n[t]. Simplify your result and answer the following questions:
[NOTE: Throughout this question, assume that and are very small positive quantities such that n[t] and n[t]2 are always less than one.]
Write down the recursion equation for the frequency of A at time t+1 as a function of its frequency at time t (use p[t] for the frequency of A).
What is the change in frequency of allele A from one generation to the next (ie find
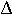 p)?
p)?
Perform a Taylor Series on p with respect to s and, assuming that selection is weak, ignore s2 and higher terms. By this method, show that p = s p (1-p) + O(s2)
[Hint: This is a somewhat different use of the Taylor Series than what we've done before. Remember that the Taylor Series says that a function f(x) can be written as f(a) + x f'(a) + x2 f''(a)/2 + ...
Now, we say that p is a function of selection, f(s), and we write f(s) = f(0) + s f'(0) + s2 f''(0)/2 + ...
Dropping s2 and higher order terms, we get that f(s) is approximately f(0) + s f'(0) when s is small, where f(0) is p when s equals 0 and f'(0) is the derivative of p evaluated at the point s=0.]
Using the fact that p is approximately s p (1-p), when will the gene frequency change at the fastest rate?
[Hint: To find a maximum or a minimum of a function, take the derivative of the function with respect to the variable of interest and set this derivative to zero. Then solve the equation for the variable of interest.]
n ln(n/K). Population size tends to increase more rapidly at low population sizes under the Gompertz equation than under the logistic equation.
This point is illustrated in the following graph with n[0]=1, K=100, and =0.1. Here, r for the logistic equation was chosen to have the same expected time until 50 individuals were present in the population (19 generations).

What are the equilibria of the Gompertz equation?
When is the equilibrium (with the species present) locally stable?
Challenge: A global solution to the Gompertz equation can be found by making a substitution of variables from n to y, using y=ln(n/K). First, what is n in terms of y? Second, what is dn/dt in terms of dy/dt (you will need to use the chain rule)? Make these substitutions into the Gompertz equation, simplify, and integrate the resulting equation to obtain the general solution for the population size at all future times.
Consider the genotype of the developing individual. When the zygote is first formed, it has its original genotype (call this the non-mutant). Every cell division, there is a chance 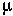 that a mutation will occur. Ignore back-mutations.
that a mutation will occur. Ignore back-mutations.
Write down the frequency of non-mutant and mutant cells as a function of the number of cell divisions since zygote formation, t.
In an organism that undergoes 100 cell divisions during development, what fraction of the cells will be mutant at a particular gene at the end of development if equals 10-7 per cell division?
Across an entire genome of 105 genes, would be approximately 10-2 per cell division. What fraction of cells in the adult will carry a mutant gene somewhere in the genome?
Assume that snowshoe hares live for a maximum of two years (consider only two age classes).
Census in the summer immediately after the breeding season. Newborn individuals survive predation with a 25% probability and survive starvation over winter with a 50% probability. Let's assume that older individuals aren't at risk of predation, but that one year old individuals still have a 50% probability of dying over winter. Individuals that are two or older never survive winter.
If the newborns survive to the next year, they will have four babies in the following spring. If the one year olds survive to the next year, they will have eight babies.
If red squirrels are removed, predation among the newborns declines, and the probability of surviving predation goes up to 75%. What effect would red squirrel removal have on the growth rate of the population and its age distribution?
Is this point an equilibrium?
Is it unstable or stable? If stable, is it locally or globally stable? Should you do a local stability analysis?
(a)
n2[t+1] = c n1[t] / n2[t]
n2[t+1] = d n1[t] + e n2[t] - f n2[t]
n2[t+1] = b n1[t]
n2[t+1] = c n2[t] + d n1[t] n2[t]
n2[t+1] = b n1[t] + c n2[t]
Describe in words how you would analyse the linear sets of equations and the non-linear sets of equations to get a sense of how the dynamical systems behave.
Consider two populations of a single species, one in a good environment (population 1) and one in a poor environment (population 2). The number of individuals in the two populations is n1 and n2, respectively.
In the good environment, the population is able to grow logistically with a carrying capacity, K1, and an intrinsic rate of growth, r1. Each generation, a proportion, m, migrate to the poor environment (this is the "source" population).
In the poor environment, each individual has R offspring. R is less than one and the population is unable to replace itself (this is the "sink" population). The sink population is maintained by the constant input of migrants every generation from the source population.
Equations describing this model are:
n2[t+1] = R n2[t] + m n1[t]
Under what conditions is the source-sink metapopulation stable?
n2[t+1] = a2 n2[t] / (1 + b2 n2[t] + c2 n1[t])
(a) Identify all the equilibrium states of the population.
(b) Three of these equilibria lack one or both species. Determine the conditions under which each of these three equilibria are stable.
(c) Gause (1932) studied competition in yeast (Saccharomyces cerevisiae and Schizosaccharomyces pombe) and estimated the following parameters: a1 = 1.2439, a2 = 1.0626, b1 = 0.0188, b1 = 0.0173, c1 = 0.0591, c2 = 0.0047. Using these numbers, determine whether any of the three equilibria studied in (b) is stable. If any equilibrium is stable, explain why the absent species does not spread in terms of the parameters of the model.
(a) Say that there is a 5% error rate in each experiment that a scientist does (ie that 5% of the time the scientist will think that they have a significant result when they don't or vice versa). On average, how many experiments will a scientist do before reaching their first false conclusion?
(b) You are tracking rabbits and observe one rabbit every 1.5 hours, on average. What is the probability that the first rabbit you see is in the last hour of an 8 hour day?
(c) You are trying to sequence a 500 basepair region of DNA, but you know that your method introduces sequencing errors at a rate of 0.001/basepair. What is the probability of obtaining the correct sequence entirely? What is the probability of getting exactly one error? What is the probability of getting more than one error?
(d) You are watching salmon swim by in a river and have, in the recent past, seen about one fish every ten minutes. You decide to wait for 10 fish to pass before heading home. How long do you expect to wait? What will the standard deviation of this estimate be? Since you realise that this is the sum of several independent events occurring, you decide it is reasonable to approximate the distribution using a normal distribution. From your statistics class, you remember that 95% of a normal distribution lies within 2 standard deviations of the mean. What is the 95% confidence interval in this case?
(a) Binomial distribution
(b) Exponential distribution
(c) Negative Binomial distribution
(d) Normal distribution
(e) Geometric distribution
(f) Gamma distribution
[Hint: The distinction between the two distributions is vaguely analogous to whether you compound interest yearly or continuously.]
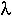 .
.
[Hint: Integrate by parts to solve this integral:

]